


Business Enterprises receive many kinds of documents related to supply chain, procurement and business administration from external agencies. These include:
- Invoices
- Purchase Orders
- Bills of Entry
- Import Licenses
- Shipping Notes
- HR Forms
- …..
- Traditionally, these documents used to be printed on paper and delivered through post or courier. Today, these come mostly as PDF files or as scanned documents attached to email. PDF (short for Portable Document Format) documents have now emerged as the most used solution for exchanging business data, particularly with trading partners.
The main advantage of PDF documents is that these when printed out, retain the exact appearance and dimensions. Also text, images, tables etc can be embedded within these. PDF Documents can also be digitally signed.
The trade-off in using PDF documents is that it is not easy to automate the extraction of text content and relevant field values from within these. This is particularly so when the text within a PDF document is embedded as an image, rather than as text.
Text within a PDF document can be “copy/pasted”, or extracted using software tools – but this only when this is embedded as “text”, and not scanned as “image”.


When the document is either in PDF format with text content embedded as image, or if the document was scanned as an image in a format like JPG, then the text content within these can be extracted only using special-purpose software capable of recognizing text characters (alphabets, numbers etc) from within an image. Such tools are known as “OCR” (Optical Character Recognition) Software.
What is more, extracting the text from within documents is only part of the problem. How do we automate the extraction of the relevant fields? Say, in case of an Invoice, we would need to extract the Vendor’s name, GST Number, Invoice Number, Invoice Date, Reference Purchase Order, Names, Quantities, Rates line items etc. For this we need to use the software techniques like “natural language processing” and “machine learning”.
Innoval’s solution for document processing not only extracts relevant fields from PDF (and from scanned images), but is also capable of posting these directly into your ERP System like SAP – after due verification and authentication as dictated by the work-flow as adopted by the organization.
Innoval’s iDeck is the perfect alternative to hiring people for manual data entry from external documents to the business software of accounting systems used by businesses.
Share this Post
About the Author
Recent Posts
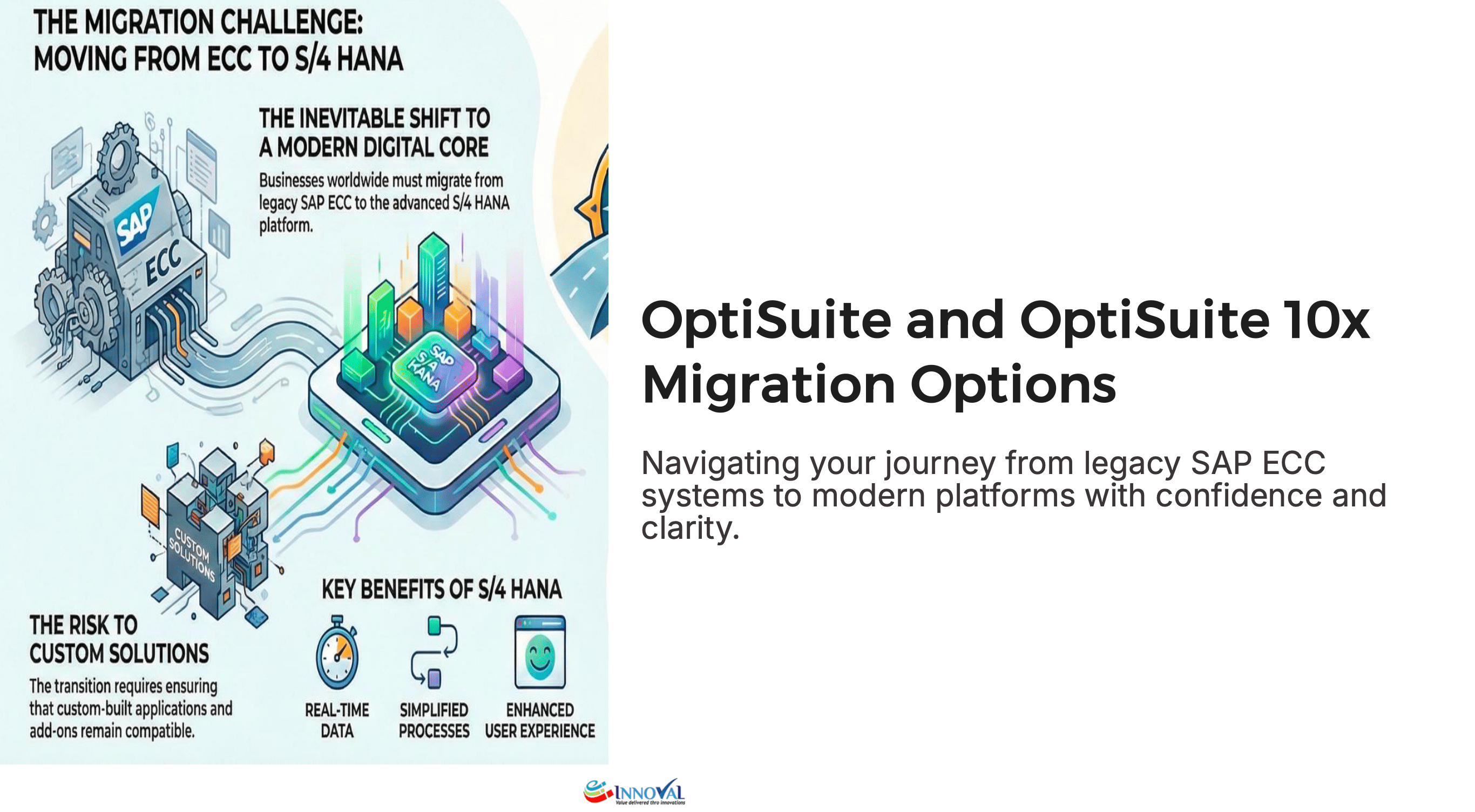
OptiSuite and OptiSuite10x Migration Options
Navigating your journey from legacy SAP ECC systems to modern …Read More »
Driving Enterprise Transformation with Practical Generative AI

Connecting ERP Systems with Government Portals in India – A Practical Guide for Exporters & Importers
In today’s fast-paced global trade environment, Indian exporters and importers …Read More »
OptiVMS by IVL: Advanced SAP Vendor Management System | 30+ Years SAP Expertise
In today’s fast-paced business environment, efficient vendor management is critical …Read More »
Streamline Your SAP Procurement with OptiVMS: The Future of Vendor Management
In the digital era, businesses need agile, efficient, and secure …Read More »
What is RISE with SAP?
RISE with SAP is SAP’s flagship Business Transformation as a …Read More »
OptiSuite10x: The All-in-One SAP Add-On for Indian Enterprises’ Compliance and Trade Needs
For Indian enterprises navigating the complexities of indirect taxation, international …Read More »
Transforming GST Compliance in SAP ERP with IVL’s OptiGST Solution
For Indian enterprises running on SAP ERP, Goods and Services …Read More »
The Importance of the Right Partner for Your SAP BTP Journey

Is Global Trade Operating with Just 3 Documents? Let’s Check the Reality.









